一、緣起
筆者曾以「賴火旺」為名義所自主發起的一系列「流行文化中的科技物件」線上議題討論,第五場《由人工智能作為主體的網路社交生態》1其延伸場次:〈從人類世界的補充成為主體——當Ai虛擬人成為人口基數〉2亦曾針對幾個子議題開展,其中一個子題即談到:新的安全機制問題:「數位性騷擾」。微軟的小冰3團隊推斷:在未來,AI Being(以小冰為數位智能框架的AI)的數量會超過人類的數量,而這些原本一直作為人類世界補充的人工智能、未來可能逐漸成為社會主體的一部分,到時我們將會面臨什麼樣的世界?同時、在——由文字、圖像、影片,聲音構成的現代網路中的種族歧視與性迫害問題都還沒解決,新的安全機制問題就已經直接挪嫁到還沒發展成熟的「元宇宙」(metaverse),數位性騷擾不是新誕生的問題,但,目前這種幾乎所有「虛擬化身」外貌都長得極其相似,唯一能辨識出差異性的只有聲音的情況下,反而讓這種「 (對被迫害者的)集體圍觀」的情況更加具象。而且很多VR中的虛擬身分是沒有身體部位的,受害者卻在騰空的狀態下被撫摸(性部位)。在這裡列舉一個案例,針對2016年女性玩家被追逐的問題,QuiVr4開發者設計了一種「力量手勢」(Power Gesture)。玩家只需在空中交叉雙臂,一股漣漪隨之擴散開來,附近其他玩家的聲音和形象都從視野中消失,玩家自己也對他人不可見,就像彼此不在同一空間。開發人員表示:「如果 VR 有能力剝奪某人的權利,對某人造成真正的心理傷害,那麼我們就將這種力量返還給玩家。」
探討被機器物件「中介」的各種人類行為和「科技治理」,已經成為筆者近年時刻關注的議題,尤其,起自2018年開始,筆者即開始進行一場——以反身份社會定義、反技術商業壟斷、和對合法系統下「非法的臉」的技術資產化進行抵抗的「穿牆實驗」:這個計畫最早也是發生在C-LAB,稱為《刷臉時代的反統治鏈》。而另一個計畫是始於2020年,由一套透過對——網路文化、算法技術、斷詞系統等多項研究,切入、去探討被機器中介後人類的敘事困境,該計畫為《精神與靈魂的治理之術》,這個計畫前期的進展與呈現形式是:透過去計算「主題標籤」(Hashtag)之間的關係和象限距離、來生成數位地貌的計畫。接著就是 2022 年,同樣起自 C-LAB 的《數位孿生技術下的未來判罰形式》,筆者在C-LAB公眾參與的座談中,以「數據追蹤與實體社會的數位孿生化程度」作為講題,即是為了該計畫所做的提問——若我們要談論數位時代的未來判罰形式,那是否勢必要先弄懂、我們的社會到底正在經歷與遭遇什麼樣的「數位孿生5化」呢?
英國金融時報6曾於2020年二月份報導:7中國正在組建一個專門研發人體情緒的識別系統,以供警方和軍方使用,進一步強化中國現有的全國監測大數據。報導說,中國的這個「人體情緒識別系統」主要用來對犯罪活動進行預測。以某個人的運動軌跡為例,全國監測系統攝像裝置所採集的有關此人所到之處監測畫面,經處理後將輸出一個具有時空坐標的規律圖,然後配上此人活動過程中的影片,進而為自動分析此人情緒特徵提供預測依據。該新聞有意思的部分在於:報導中「對操作形式的描述」其實已經不再純粹是一種辨識技術的描述,它包含一連串的社會行為。而可怕的就是「定義這個社會行為的方法」居然是來自一連串政府視角的「敘事」,比如新聞中描述:「從——辨識材料採集——時空座標的輸出——情緒影片的配對」,這原本每個環節使用的是不同的技術方案,卻被通過同一個「治理敘事」串連起來。這也成了筆者後續用來「建構與串接」創作方法的參考模型之一。
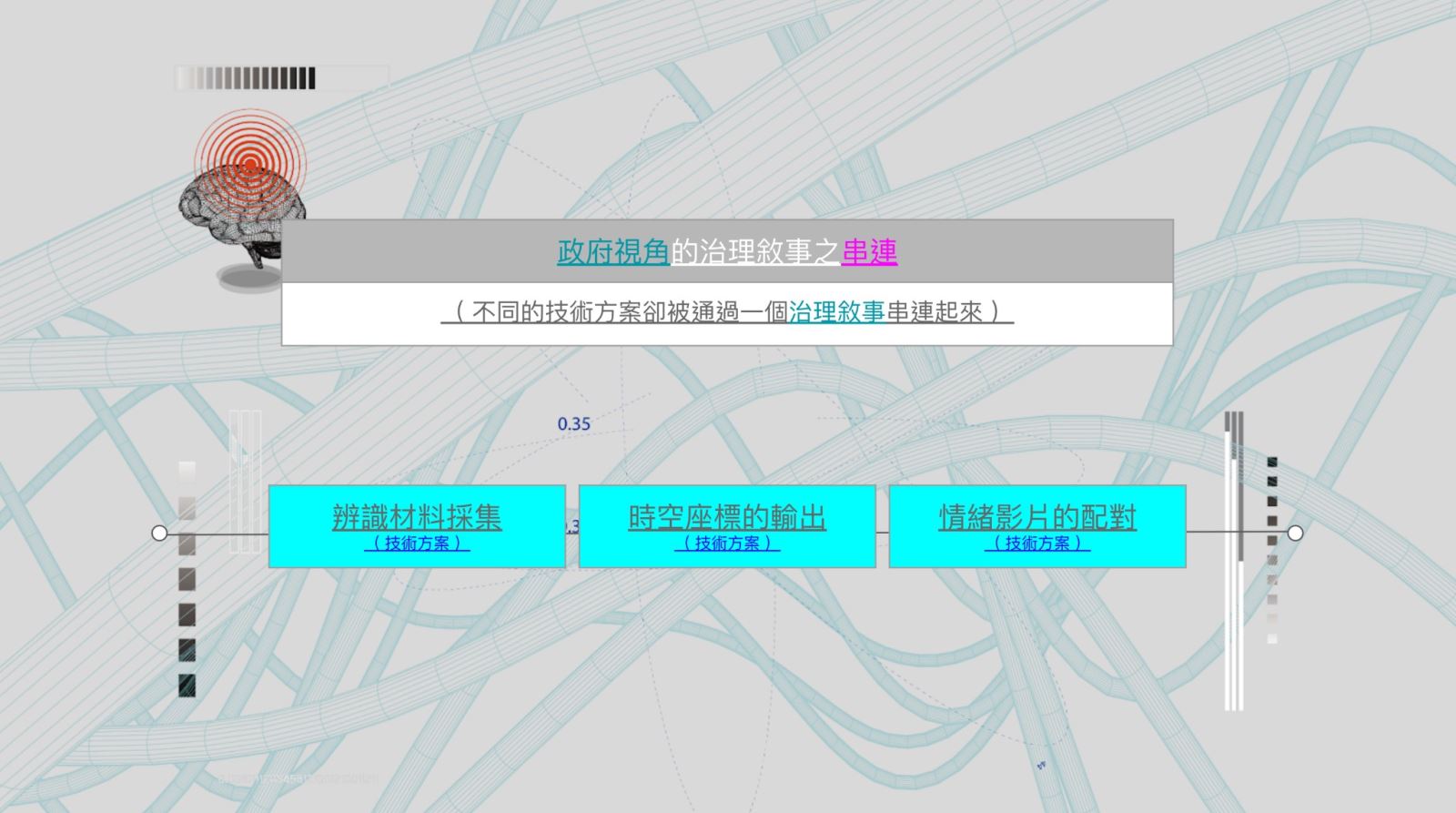
【圖1】筆者後續用來「建構與串接」創作方法的參考模型之一
二、孿生技術的測量:測量的設計
人類行為是一個多層次的概念,它通常需要個人層面的度量(或測量),來推斷「行為」、「態度」和「屬性」在集體層面的分佈。在不知道系統是如何設計的情況下,我們很容易把一些所謂的「社會動機」歸因在單純由「演算法」決定或驅動的行為。而這些系統所捕捉到的數據,也存在系統性的偏差——比如任何一個與你通過手機交談的人,都可能通過:Line、Messenger、Zoom、Skype(有時候你甚至要掛斷電話後、去檢閱你的通話紀錄,才能判斷剛才對方是從「哪套系統」與你通聯的),這些連接我們溝通的「橋樑」、不再是由同一套系統或設備上接通進來的。複雜的通訊網絡也反映了「社會技術」的複雜性,尤其現在「異地同步語音中介通信」這類技術,已經很容易被描述為「電話通話」——我們現在不只是「訊息碎片化」,也處在一種「技術碎片化」的時代。而「技術碎片化」的後果是:我們發現的所謂的「答案」,可能是在「與我們類似」、但「不同的技術」中通過「行為」去測量出來的。對於系統級數據,人們可能會認為每個人都被數據代表了,因為所有用戶的操作都在數據集8中。網際網路的推動下,通訊技術的發展也導致了行為的分裂,形成不同的「數據倉庫」。9
(一)、實體社會的孿生化程度
科學很少會超出科學家所能觀察和測量的範圍,但,有時候,觀察會遠超科學理解的範圍,21世紀、正為了人類社會的研究提供了這樣一個時刻。今天能觀察到的人類行為遠比20世紀末所能想像的要多得多。比如:我們的人際交往、行動和許多日常行為,都有可能被用於科學研究;有時通過「有目的的儀器」來實現科研目標(像是:衛星圖像),但,有更多時候,這些目標實際上是事後才有的想法(例如:Twitter的數據流)。所以在談怎麼去處理《數位孿生技術下的未來判罰形式》之前,筆者必須先瞭解:人類正在透過哪些科學測量及其原理的視角,去「創造結構化的表示」、和「量化人類行為」的技術,與這些測量正在面臨到的一些關於數據在概念上、計算上和倫理上的挑戰。才能後續延伸討論到筆者所試圖想要提及——我們如何「捕捉」這些技術現況,和正在快速被改變的社會現實?或者說,我們需要哪些新的方法來管理、使用和分析這些數據呢? 從汽車追蹤設備到網路瀏覽,人類活動中、基本上已經充滿各種感測器(Sensor)技術的應用。例如:衛星會定期去描繪地球、並把這些數位化,另外一些像是:書籍、廣播和電視節目,等等-非結構化的數據,也逐漸在轉換成數據技術。也就是說,在21世紀,我們人類的行為——從流動、移動,到訊息消費,再到各式各樣的人際交往,越來越多都能被紀錄並且有可能被計算處理。在過去的通信技術,從傳統郵件、印刷品再到傳真,通常只能留下很少的,耐用性較高、和少數人能取得的人工製品。現在這些東西都能透過各種運算和計算來獲得,書籍的數位化就是一個典型的案例——這種「書籍的數位化」可以使我們能夠對幾百年前的人類所表達的大量「語料庫」10進行分析。移動網路和網路通訊領域的技術變革已經徹底改變——我們對自己、和我們與世界是「如何互動」上的理解,這些技術變革能讓我們把「不可測量」的事物和東西變得可測量。
(二)、社會和測量的不穩定邏輯
治理人類的「社會規則」所產生的不穩定性問題一部分來自:收集人們各種行為數據的「社會技術系統」的介入,這些「機器中介系統」會加劇這種不穩定性,而這些系統也正在積極(或有意地)改變社會科學將要研究的「社會世界」——我們後面透過「知識社會學理論」中的一些「反身性」案例,來理解這種「不穩定邏輯」的產生。那什麼是「反身性」呢?社會學中「反身性」指的是:將「社會現實」與我們「設計用於解釋社會現實的理論和量度」連結起來的循環。比如「從眾效應」和「劣勢效應」——這些效應反映了「測量」對「態度」和「行為」的影響,以及我們的測量如何扭曲他們原本「試圖設計用來監測的現象」(選民)。反過來:公共衛生、執法、量刑、教育和招聘等領域的演算法決策也會放大這些扭曲。
反身性還會表現為:觀察者效應的形式。比如:當——人們知道自己正在被觀察時,就會改變自己的行為。數位技術創造了「反身性」問題的新版本,也就是:放大了社會指標中固有的表現等方面。舉個案例:當 Google在2008年啟動「流感趨勢」(Flu Trends Project)11項目時,原本目標是使用「搜索」和「查詢」來估算「流感症狀」在人群中的流行程度,結果在2013年,這個項目卻大大高估了流感的峰值。其中一個原因是:有缺陷的假設——也就是「搜索行為」本身是由外部事件(比如流感症狀)所驅動的。實際上,Google的算法也在推動這些模式。比如:嘗試通過「推薦搜索的關鍵詞」來預測用戶的意圖,簡單說,Google扭曲了用戶原本可以看到的訊息——造成了:對觀察到的現象的反應,改變了現象本身。這就是「反身性」不穩定邏輯。
而「模糊處理策略」則代表了「觀察者效應」的另一個版本,比如:我們現在可以輕而易舉地透過——故意添加「模糊」或「誤導性訊息」來干擾數據收集,從而去中斷測量。模糊處理的例子包括:編輯輪廓照片,以防止一些臉部視覺辨識技術(筆者於2018年時發起的藝術計畫《刷臉時代的反統治鏈》,即是透過模糊或誤導性訊息來干擾中國幾大支付平台的臉部視覺辨識數據的技術框架)。或者:在瀏覽網頁時,去使用「虛擬專用網路(也就是VPN)」來隱藏自己的位置;又或使用「群組身份(例如,許多人共用一個用戶帳戶)」來掩蓋單個用戶行為的細節。這裡的「反身性」的循環,是因人們意識到自己的行為痕跡正在被反饋到「測量」和「監視」中而產生的,因此這些行為的含義是「有意地被改變的」。廣義的說,這是類似於一種「受訪者在對調查人員說謊」的舉動。而且,由於那些——了解「正在發生的監視」以及「如何實施模糊處理」,來解決這些問題所需的技能,並不是隨機分佈在人群中的,因此把數據以這種方式改變的個人也不會是隨機的。
再例如:進行訪談的人的「性別」、「年齡」和「種族」,也可能會極大地改變受訪者提供的答案。像這些「反身性」問題,現在幾乎已經被嵌入於各種監測和預測人類行為的工具中了,也就是:「社會現實」與「被我們用來分析社會現實而設計的量度方法」,已經被聯繫起來並且加強循環。簡單講,這就好像哈伯太空望遠鏡(Hubble Space Telescope)在觀測恆星時的同時,卻又組構了恆星的位置和行為類似——例如:社交媒體不僅捕捉了人類的行為,也有可能改變人類社會的重要模式:像是訊息流動的速度、媒體製作的範圍,以及「負責界定輿論」的行為者,等。因為組織人類社會的原則是有流動性的,因此一個原本特定測量的意義也會造成「演變」(是演變不是改變)。新興的「社會技術系統」(Sociotechnical System),12也正在降低一些用來衡量人類行為的「舊科學工具」的重要性,這導致社會科學必須適應新型數據的原因。
像是:國內生產毛額(也就是GDP)和「地域流動性」等關鍵概念,在現有的衡量標準中,仍然受限制於20世紀數據的部分優缺點。如果我們只對「舊的衡量標準」進行評估,我們只會複製他們(這些舊的衡量標準)的缺點——像是把20世紀的金本位13誤認為是客觀真理,這件事。又比如過往選舉研究,會對有關選舉的電台、電視台的「消費標準」所做的提問,像是:你會被問及——「你在電台或電視台聽過幾次關於選舉的討論 」這種提問。這種提問是由:很有限的、「離散單元」14所組成的「媒體消費」結構,也是屬於廣播時代技術的產物。這類關於「次數調查」的提問,和當代、現下的人們,如何訪問(瀏覽)數位媒體根本沒有多大關係。上述這些都是在「定量社會科學」15的早期發展起來的一些對行為的衡量(測量)方法。那新的量度(測量)方法有哪些核心原則呢?(因為這涉及新的社會科學研究方法,下一段落再展開解釋)。
(三)、追蹤數據到底在測量什麼?
大多數使用「行為追踪數據」去進行測量的目的是——從儀器產生的「原始數據」中提取意義。所有的「科學數據儀器」都面臨著這個問題,但是、當我們使用從:「為了其他目的而設計的系統中」回收而來的數據時,從「原始數據」到「有意義的度量」往往跨度非常大(詮釋上也非常困難)。比如:未經處理,和未報告特定緯度和經度的移動電話的移動數據,它在很大程度上是無趣的,而、有經過處理的數據,會使得我們能夠測量到數據和數據的:接近度(親進度)、移動,和其他與社會相關的概念。總體來說:21 世紀的觀測數據不是為研究而設計的,在能夠利用這些數據回答科學研究問題之前,我們需要把這些觀測數據與已知的概念連結起來。而度量的「意義」則部分來自於「理論」:也就是「應用現有知識去解釋數位訊號的理論」,並去帶動或驅動——設計可以克服使用儀器化行為數據的許多問題。相反地,缺乏理論化的特殊操作會使研究結果難以解釋,並且在不同的研究中呈現出不一致。
舉個例子:假如我們一起來思考——如何使用「移動的、流動性的數據」來研究COVID-19的傳播。以2019年中國為例:疫情中心還在中國時,有很多研究會使用「即時性的旅行數據」來追蹤「武漢」到「中國其他省份」的人員移動,研究人員發現:來自「武漢的人口流動」對於冠狀病毒是否會「流入一個地區」具有強烈的預測性。於是當地疾控人員預測了病毒後續的傳播。在這些研究中,就有一個被很好地「理論化」的過程——就是,假設:病毒的傳播是由個體的接近(親近)所驅動的。再比如:研究人員利用「手機數據」設計了一種基於「接近度」(或稱親進度)的測量方法,用來記錄人們接近彼此的時間(例如:臺灣社交距離App的部分用途)。這些指標,可以用於各種各樣有用的目的。它們可以作為「關係強度」的指標,也可以作為一種「追踪病毒傳染途徑」的方法。但是,這種方法也會有錯誤的可能性:例如,兩個藍牙訊息標示、所顯示設備互相接近的人,他們可能中間隔著一堵牆,或者可能只是從同一個插座給手機充電。
即便近年有數千篇基於Twitter數據的論文,但,社交媒體學者仍然發現:要識別個人用戶的統計特徵,仍然是一個巨大挑戰。除此之外,其實研究人員也仍然無法可靠地去區分「人類」和「非人類」(例如,機器人、集體帳號或組織)。因此,Twitter的大部分研究,都是對帳號或推文進行「推斷」;很少有Twitter的研究,可以合理地宣稱——自己是在對「人類的行為」進行陳述。然後、即使「人類是特定行為的來源」,但,將「特定行為」歸因於「特定的人」也可能會遇到一些挑戰。例如,在廣播電視發展的早期的受眾研究也遭遇到了「多成員家庭」的挑戰類似——也就如筆者前述所提到的,當調查人員打了一通調查電話去詢問觀眾「一共聽多少次的選舉演講內容」根本不精確,因為一支電話不代表是一個用戶、而是一個家庭,家庭成員中,有人可能同時喜歡兒童漫畫和有線新聞(或頻道中的特定政論節目),事實上、這通電話中就這涉及兩個不同的個體。因此,當行為是「人(比如:兩個人使用同一個Netflix帳戶)」、或「 設備(在智慧型手機和電腦上查看Twitter的同一個人)」之間的共享時,技術設備可能會產生誤導。另一個會造成誤導更嚴重的問題是:「設備——人」無法配對,也可能會隨著「時間的推移」迅速演變。比如:有線新聞的瀏覽者可能是祖父母,而Xbox16用戶可能是孫輩。然而,這些模型中包含的數據總是來自過去(而非即時或當下),而且度量之間的關係本身就是不穩定的。這種數據誤判我們還可以針對下列兩項進行深度討論。
三、碎片化間的設計
(一)、「數據倉庫」與演算法的混亂
在不知道系統是如何設計的情況下,我們很容易把一些所謂的「社會動機」歸因在單純由「演算法」決定或驅動的行為。而這些系統所捕捉到的數據,也存在系統性的偏差——比如任何一個與你通過手機交談的人,都可能通過:Line、Messenger、Zoom、Skype(有時候你甚至要掛斷電話後、去檢閱你的通話紀錄,才能判斷剛才對方是從「哪套系統」與你通聯的),這些連接我們溝通的「橋樑」、不再是由同一套系統或設備上接通進來的。這些複雜的通訊網絡也反映了「社會技術」的複雜性。尤其現在「異地同步語音中介通信」這類技術,已經很容易被描述為「電話通話」。我們現在不只是「訊息碎片化」,也處在一種「技術碎片化」的時代。而「技術碎片化」的後果是:我們發現的所謂的「答案」,可能是在「與我們類似」、但「不同的技術」中通過「行為」去測量出來的。對於系統級數據,人們可能會認為每個人都被數據代表了,因為所有用戶的操作都在數據集中。網際網路的推動下,通訊技術的發展也導致了行為的分裂,形成不同的「數據倉庫」。
這裡的混亂指的是:我們無法區分代表「典型人類行為的訊號」和「數位平台的規則所產生的訊號」。這也是為筆者在透過Discord17伺服器所舉辦的「流行文化中的科技物件」系列線上議題,18總不是單單去談「文化現象」而也涉及去談論到各個數位平台、串流平台,和不同國家介面所使用的「法規」與「規章」差異的主因。因為:在不知道系統是如何設計的情況下,我們很容易把一些所謂的「社會動機」歸因在單純由「演算法」決定或驅動的行為。這邊列舉個例子:如果Twitter的訊息流突然開始把體育內容的優先級別提高,在用戶對體育的潛在興趣沒有任何變化時,也可能會發現誰贏得了奧運會比賽——這種變化往往很難被發現,因為它們有時是在沒有經過通知的情況下、被引入的,也是因為它們可能會不均勻地展開,先影響某些用戶群體。這種機制也以更微妙的方式發揮作用,比如:Twitter系統性的建議你回饋關注那些已經關注你的人,那就可以促進我們回報社會關係的自然傾向。更普遍地說,網際網路公司的目標就是「操縱人類行為」,以增加其平台上的參與度(無論是Facebook、Twitter和Instagram,中國的抖音、19小紅書20或微博無一例外),或一些引導我們在平台上消費和支出的(諸如:Amazon或Ebay)也是相同取向。再例如:眾所周知,Twitter上的情感表達方式很難被電腦解碼,因為它們通常會被「譏諷」、「反串」21和「誇張」所阻礙。
對於系統級數據,人們可能會認為每個人都被數據代表了,因為所有用戶的操作都在數據集中。然而,在這種情況下,採樣針對的是那些收集數據的「系統用戶」、和「最活躍的成員」。這充其量只是對被調查平台的「便利普查」而不是對整個人口的普查。如果科學目標是「對平台上的人做出陳述」,那麼這個普查可能是令人信服的。然而,任何跨越這一平台的概括都必須被更加批判性地看待。這是Twitter研究的一個特殊問題,Twitter是最常被引用的新興數據來源,儘管只有大約20%的美國人在使用Twitter,並且在大多數其他國家甚至更不流行。尤其:社交媒體平台的用戶並不能真實反映網際網路用戶的總體人口特徵,也不能反映興趣等其他屬性。當只研究平台用戶群體的一個「子集」22時,泛化23問題就會被放大。其他在「普適性」方面的關鍵問題,還包括:「不同的平台」會引發「系統性的」不同行為。例如,同一個人在 Facebook 和Twitter上的表現往往不同。更準確地說:一些人類行為,其實是高度依賴於環境,如果我們只能在工作、家庭或宗教環境中觀察同一個人,我們可能會對人性做出完全不同的結論。
(二)、新興數據來源的泛化與抽樣的系統性偏差
社交媒體平台的用戶並不能真實反映網際網路用戶的總體人口特徵,也不能反映興趣等其他屬性。當只研究平台用戶群體的一個「子集」時,泛化問題就會被放大。其他在「普適性」方面的關鍵問題,還包括:「不同的平台」會引發「系統性的」不同行為。例如,同一個人在Facebook和Twitter上的表現往往不同。更準確地說:一些人類行為,其實是高度依賴於環境,如果我們只能在工作、家庭或宗教環境中觀察同一個人,我們可能會對人性做出完全不同的結論。「普適性」不僅是關於人口的函數,而且是「特定觀測環境的函數」,也會根據研究問題的不同,演變成:這可能是問題,也可能不是問題。一個「被明確定義的問題」和「人群」會有助於:確定度量(測量)結果與研究意圖的吻合程度。
以下列這個案例來解釋抽樣研究模式所造成的系統性偏差——例如:通過電子郵件(Email)聯繫受訪者,其實很容易「系統性地」排除了那些「無家可歸的人群(例如遊民)」。而「電話調查」排除了「沒有電話的人群」,親自進行的調查,也取決於人們對與陌生人這種互動方式的舒適度和信任度。而「觀察行為流」也可能受到類似偏差的影響。首先:收集數據的儀器通常是個人擁有的「消費品(例如,行動電話或電腦)」,因此成本是一個障礙。其次,這些工具通常是由針對有錢人的企業商業模式驅動的。第三,當人們選擇「不使用隱私服務」時,那些更關心或更了解隱私問題的人在跟踪行為系統中的代表性可能會降低(比如很多人時常聲稱自己在「逃離「臉書」( Facebook )」)。不過、這些「數據流」具有一些關鍵的補償特性。像是「感測技術」可能會填補重要的數據空白,讓那些原本會被從地圖上抹去的人變得可見。例如,在沒有家庭收入和消費調查的情況下,衛星圖像被用於建立全球南方(Global South)的財富和貧困指標。24現代技術的普遍性意味著,在很多情況下,其實可能比傳統的數據收集機制還要具備優勢,例如——擁有一部手機比擁有一個家要便宜。衛星圖像被用於建立全球南方(Global South)的財富和貧困指標這件事的思考,與美國社會學家杜波依斯在19世紀末和20世紀初用於研究非裔美國人個人的行政數據有相似之處:一個實行種族等級制度的行政國家的數據,肯定不是中立的,但,在提供社會中——最危險地位的人(弱勢、貧窮群體)的可見度方面仍然具有關鍵價值。其實20世紀的方法通常不適合研究一些社會現實,但,也許21 世紀的社會理論,能夠利用「微觀層面的行為數據」,來理解「相互依存的結構」能如何產生某些「宏觀層面」的模式。
(三)、測量的獲取和道德之間的關係
和哈伯太空望遠鏡(Hubble Space Telescope)的數據相比,來自「社會技術系統」的新興數據流,提出了兩個額外的挑戰。首先,哈伯太空望遠鏡是由科學機構控制的,其目標想必是回答科學問題。Twitter等平台的製度目標顯然不是回答科學問題。因此,第一個問題是:什麼是可以被度量的?第二:人類作為研究的參與者提出了「道德問題」,而遙遠的星系顯然沒有。所以、接下來的問題是:應該度量什麼?一般來說,任何控制研究人員感興趣的數據的「私人機構」,在沒有相反規定的情況下、反而都可以根據自己的選擇決定數據訪問的「條款」。像Twitter和Facebook這種平台的行為,就是公眾關心的科學問題的焦點(比如:一個平台是否放大了錯誤信息的傳播?平台對仇恨言論的應對舉措是什麼?),因為這些平台的數據會使這種「控制」成為一個嚴重的問題。而、學術界在這些領域的一項職責,就是向公眾提供關於這些重要問題的信息。關於什麼可以被度量(測量)的一個推論必須是:如果「被質疑的權力」(例如:中國這個政治體與其底下建造的數據王國)控制著——對「用來構建真相的數據 」的「訪問」(瀏覽、查閱、檢視),那麼人們有可能對權力說真話嗎?如果沒有,那是否有可能允許從任何可信任的確定系統中去提取度量方法?我們可以從下列針對數據收集的五大倫理問題來逐一探討。
四、數據收集的五大倫理問題
(一)、研究人員(或稱數據收集員)在考慮「數據收集場景」時(例如:通過洩密或黑客攻擊)的道德義務是什麼?
儘管知情同意是對人類參與者研究的基礎,但第三方獲得的匿名數據通常不被視為「人類參與者數據」,因此不受機構審查委員會的審視。在一個2021年的例子中,來自極右翼社交網絡Parler(即Google與Amazon聯手封殺川普後,其支持者們所群聚之社交平臺),這個平台的超過70Gb的數據在2021年1月初被公開發布,包括GPS衍生的位置的數據。25該起事件當中,「研究人員是否能夠道德地分析這一數據集」,其實是一個引發持續爭論的話題,特別是考慮到該網站被判定是用於策劃2021年1月6日美國國會大廈暴動(該政治行為在輿論上被判定為惡性行為)。其實普通人面對這些不知道怎麼流出來的數據,是由哪些不同系統、和如何跟踪(平台成員)訊息的——無論是通過手機的移動數據或者瀏覽數據。那麼,當第三方(諸如研究員角色)去追踪這些目標(被判定有特定政治立場和意識形態的人群),他們的研究與道德準則又是什麼?
(二)、研究團體(或稱數據收集團體)如何解決「數據匿名化技術」(例如通過添加「噪聲」)帶來的權衡問題?
取消標識(或標籤)的「匿名數據」可以分為:「無法重新標識(或標籤)的類型 」、或是:「可以重新標識(或標籤)的類型 」。圍繞差分26隱私出現了一些允許向「數據集」添加「噪音」的方法,從而一定程度上保證了數據的匿名性,使這筆資訊能夠可靠地進行「重新識別」。然而這裡存在一個折衷,因為增強隱私的噪音添加會降低數據的效用。這是《Social Science One project》27中採用的方法,該項目提供了對Facebook數據的分析訪問。被授予訪問權限的團隊面臨的難題之一,是:「結果數據」是否保留了回答他們問題的價值(注:一些作者參與了《Social Science One project》 和 《Facebook 2020 Election Research Project》)。28
(三)、對於公開可見的行為(如:社交媒體貼文),何種「隱私期望」是屬於合理的?
研究人員(或數據採集者)什麼時候應該避免提及(在出版物或演示中):因為可能引起負面關注或騷擾——諸如用戶名和完整的社交媒體消息之類的信息?一些人認為,自動匿名公開數據可能也不是正確的方法,相反,應該諮詢內容創作者他們的偏好。
(四)、我們如何管理信息溢出,即——從同意的個人收集的數據洩露了關於他人的信息,且他人並不知情或不同意(像是一對一聊天截圖被流出)?
在一個信息和洞察網絡化的世界裡,一個人透露給其他人的信息經常會「溢出」。網絡媒體的功能,顧名思義:就是促進人際間的可視性。例如,共享電子郵件數據的個人,必須提供來自其他個人的信息。劍橋分析公司(Cambridge Analytica)的「醜聞」29表明了這種網絡信息披露的危險性,在這件事中,個人使用了Facebook應用,而Facebook應用又提供了訪問這些用戶朋友行為數據的途徑。然而,「訊息溢出」的風險是一個更為普遍的原則,這在數位追踪數據中並不新鮮:個人披露幾乎總存在潛在的溢出。例如,一個人的基因數據有可能提供關於其「近親」的線索;並且幾乎所有關於個人的數據都提供了關於他人的信息。一個人對其政治偏好的回應可以讓人了解到其他家庭成員的偏好,關於一個人吸毒的信息可以讓人了解對此人朋友的潛在吸毒情況。
(五)、我們如何確保「 邊緣群體 」在研究中得到充分和準確的代表?
與傳統的20世紀方法相比,當數位形式的度量,能夠更好地代表邊緣群體時,我們的道德義務就應該是使用它們,正如上文提到的:衛星圖像被用於建立全球南方(Global South)的財富和貧困指標這件事的思考所強調的那樣,社會面臨的選擇、不是「數位技術是否將被用來度量人類行為」,而是在被公司或國家「監控」(或廣義稱之為「監管」)之外的任何人,能在何時、或如何,以及是否能夠獲得這些數據。理想的情況是:為服務更詳細的政策、和對針對性的問題進行干預措施來提供訊息,而讓大規模的數位數據源將流入各項度量(測量)。所以面對個人的數據、訊號、資訊,等採集、度量(測量)不僅僅是一刀切,以「隱私權」一以概之抵抗的舉措,因為這些舉措往往對少數群體效果不佳。
五、小結
2020年首爾地方法院一審宣判,3025歲的主嫌趙主斌,以違反《兒童青少年保護法》、組織犯罪等罪名,處40年有期徒刑、電子腳鐐30年、追徵一億韓元(約新台幣257萬元),其他共犯,包括24歲的N號房創始者文亨旭,被求處無期徒刑;管理聊天室的18歲男性姜勳、19歲男性李元昊,被求處30年有期徒刑、15年電子腳鐐。另外包含持有影像者在內,共計已有67人被捕,調查與判決仍在進行中。韓國N號房事件也讓數位性犯罪的流通網(Telegram、暗網、色情網站、網路硬碟)和這些工具上的數位圍觀者的判罰議題浮上檯面。2020年5月,韓國國會通過《N號房防治法》將最低合法性交年齡,從13歲提高到16歲,另外持有、購買、儲存、觀看非法色情影像,未來也將面臨3年以下徒刑、或是3,000萬韓元(約台幣73萬)以下的刑罰。根據《BBC》報導,起初,韓國 NGO「網路性暴力支持中心」(Cyber Sexual Violence Response Centre)會協助尋找、檢舉、刪除這些性侵害影片,但是成員很快就發現,這些都不是最有效的做法。今天面對的是網路空間中不同工具、數位物件與介面的連結,當人與社群介入其中執行一連串去中心化的「設計」,每一個連結與轉碼的「轉導」都夾帶著推斷式(思辨式)的測量,意即通過這些系列式去中心的測量讓不同質性的數據得以被整合演算並驅動網路空間中的事件與意志。